Pflanzen als Umweltsensoren: Citizen-Science-Daten zeigen den Einfluss von Urbanisierung auf Klima und Böden
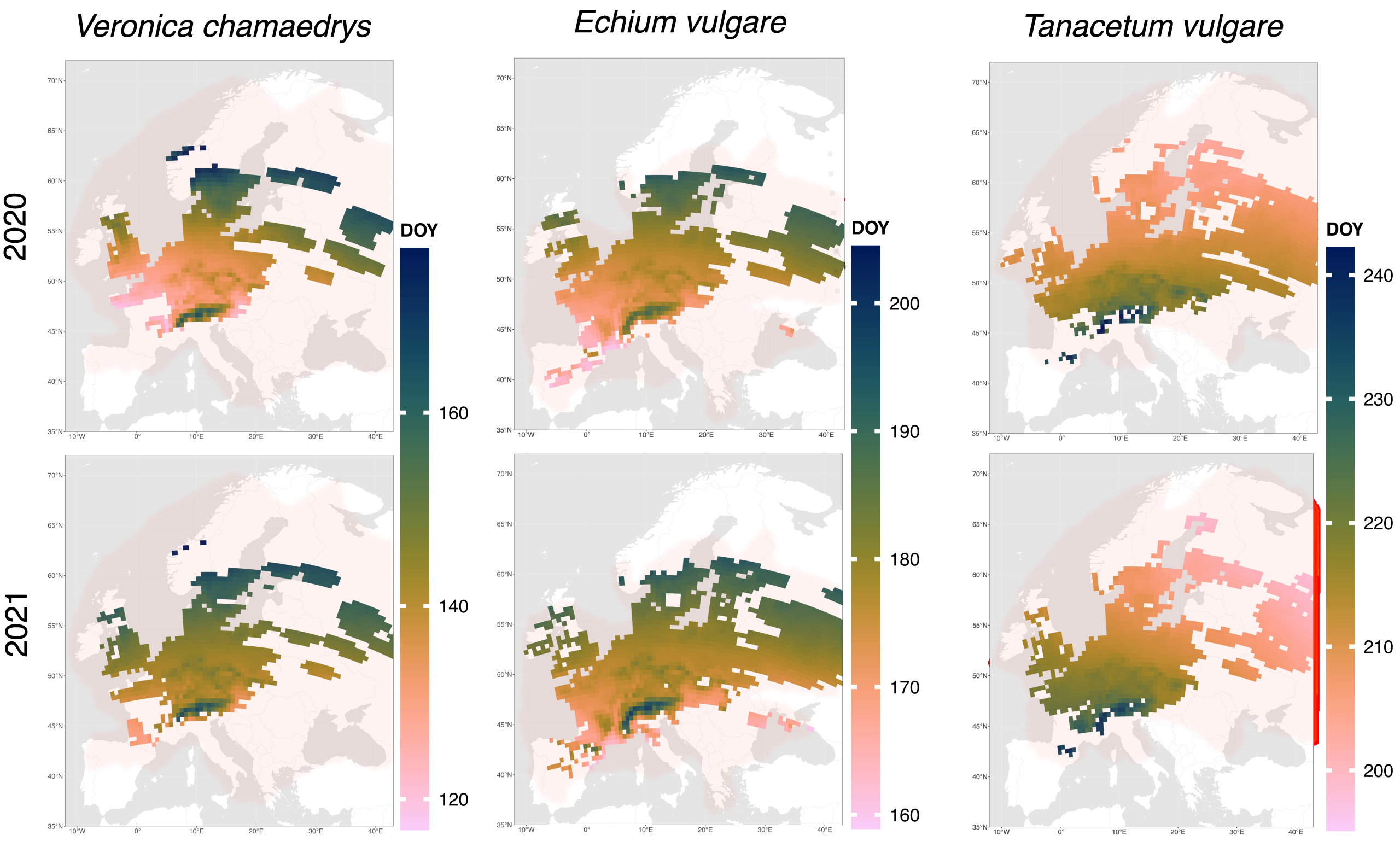
Wie ist es um die Umwelt unserer Städte bestellt? Pflanzen spiegeln die städtischen Klima- und Bodeneigenschaften präzise wider. Mit Hilfe von über 80 Millionen Beobachtungen aus Pflanzenbestimmungs-Apps gelang es Forschenden des Max-Planck-Instituts für Biogeochemie nun, ein detailliertes Bild kleinräumiger Klima- und Bodenbedingungen für 326 europäische Städte zu zeichnen. Ergebnis: Bebaute Flächen sind wärmer und trockener; ihre Böden sind stärker mechanisch bearbeitet sowie salziger und alkalischer als die städtischer Grünflächen wie Parks oder Wälder. Während sich bebaute Flächen europaweit stark ähneln, bewahren städtische Wälder die natürliche Vielfalt ihrer ursprünglichen Umweltfaktoren. Die Studie erschien heute im Fachjournal Nature Cities.
Pflanzen als lebende Sensoren für städtische Umwelt
Bis 2050 werden rund 70 % der Weltbevölkerung in Städten leben. Dennoch sind urbane Umweltbedingungen bislang kaum oder nur grob erfasst. Eine neue Studie, erschienen im Fachjournal Nature Cities, zeigt, wie Pflanzen kleinräumige Klima- und Bodeneigenschaften erfassen und Hinweise auf menschliche Einflüsse liefern. Grundlage sind Beobachtungen von Pflanzen, die über Bestimmungs-Apps wie beispielsweise Flora Incognita gesammelt wurden.
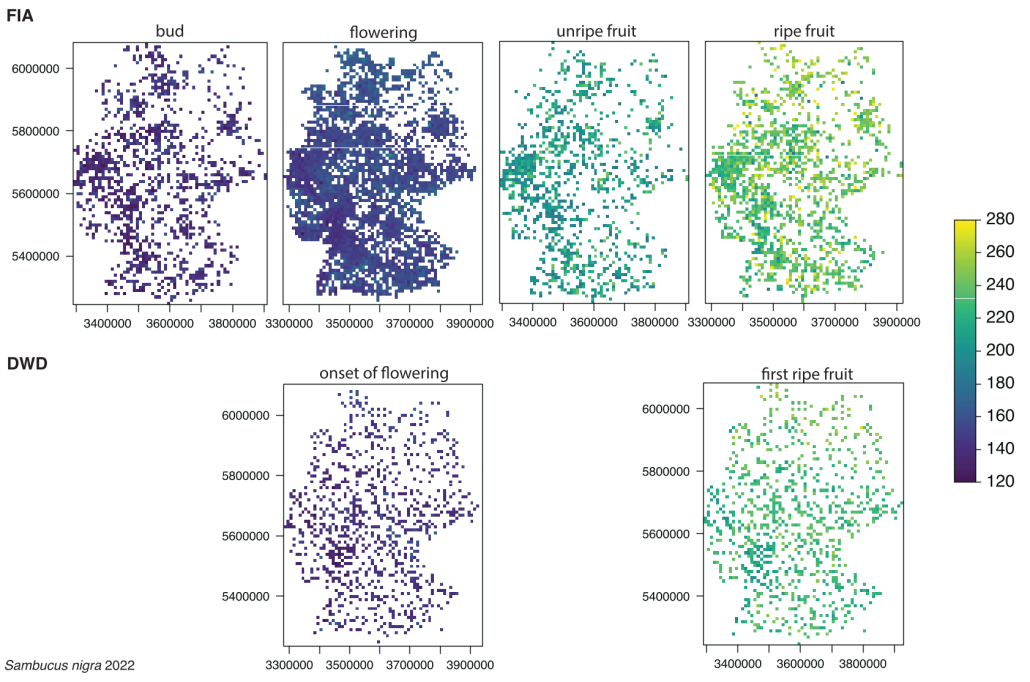
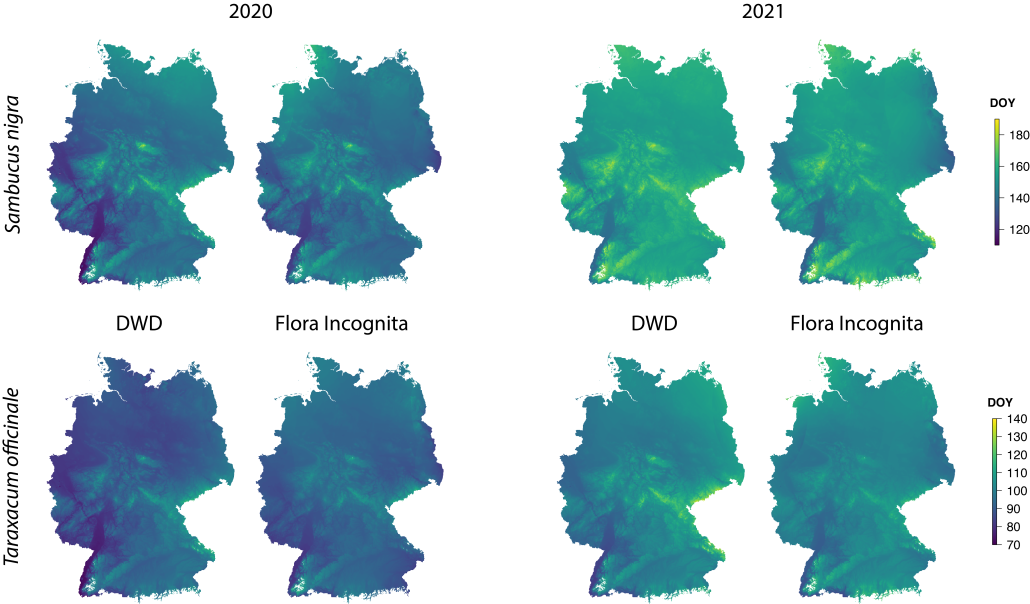
„Pflanzen wachsen dort, wo ihre Standortansprüche erfüllt sind“, erklärt Dr. Susanne Tautenhahn, Erstautorin der Studie. „Brennnesseln zeigen nährstoffreiche Böden an, Sumpfdotterblumen bevorzugen feuchte Standorte und Salzschwaden wachsen entlang gesalzener Straßen.“ So lassen sich Faktoren wie Temperatur, Bodenfeuchte, pH-Wert, Salzgehalt oder Störung über Pflanzenerkennung indirekt erfassen.
Gerade in Städten kann dieser Ansatz sein volles Potenzial entfalten: Die große Zahl an Beobachtungen liefert präzise Daten, während klassische Messungen oft an der räumlichen Heterogenität scheitern. „Selbst zwischen Beton und Asphalt zeigen Pflanzen sehr genau, wie warm oder trocken ein Standort ist, oder ob der Boden stark bearbeitet wurde“, so Tautenhahn.
Altes Wissen trifft neue Daten
Die Vision entstand, jahrzehntelanges Wissen über Pflanzen als lebende Umweltsensoren mit großskaligen Citizen-Science-Daten zu verbinden. Daraus entwickelte sich ein neuer, pflanzenbasierter Ansatz, um kleinräumige Klima- und Bodenbedingungen in Städten zu erfassen.
„Das Vorgehen ist vergleichbar mit Remote sensing – allerdings mit Pflanzen, Smartphones und einer engagierten “Crowd” von Bürger:innen anstelle von Satelliten“, erklärt Tautenhahn. „Diese neue Form der Umweltbeobachtung nennen wir Mobile Crowd Sensing of Environments (MCSE).“
Das interdisziplinäre Autor:innen-Team vereint Expertise aus Botanik, Ökologie, Bodenkunde, Computer Vision, Citizen Science und Fernerkundung. Jede Perspektive half dabei, aus den Pflanzenbeobachtungen der Bürger:innen ein bisher unbekanntes, detailliertes Bild städtischer Umweltbedingungen zu gewinnen.
„Erst vor Kurzem wurde das zuvor überwiegend regionale Wissen zu den Standortansprüchen individueller Pflanzenarten – ausgedrückt in den sogenannten ökologischen Zeigerwerten – europaweit zusammengeführt“, sagt Prof. Dr. Jürgen Dengler. „So lassen sich Umweltbedingungen wie Bodenfeuchte, Nährstoffgehalt oder Licht – aber auch Störungen wie intensive Bodenbearbeitung – erstmals über ganz Europa hinweg sichtbar machen“, ergänzt Prof. Dr. Milan Chytrý. Beide waren maßgeblich an der europaweiten Vereinheitlichung der in dieser Studie verwendeten ökologischen Zeigerwertsysteme beteiligt.
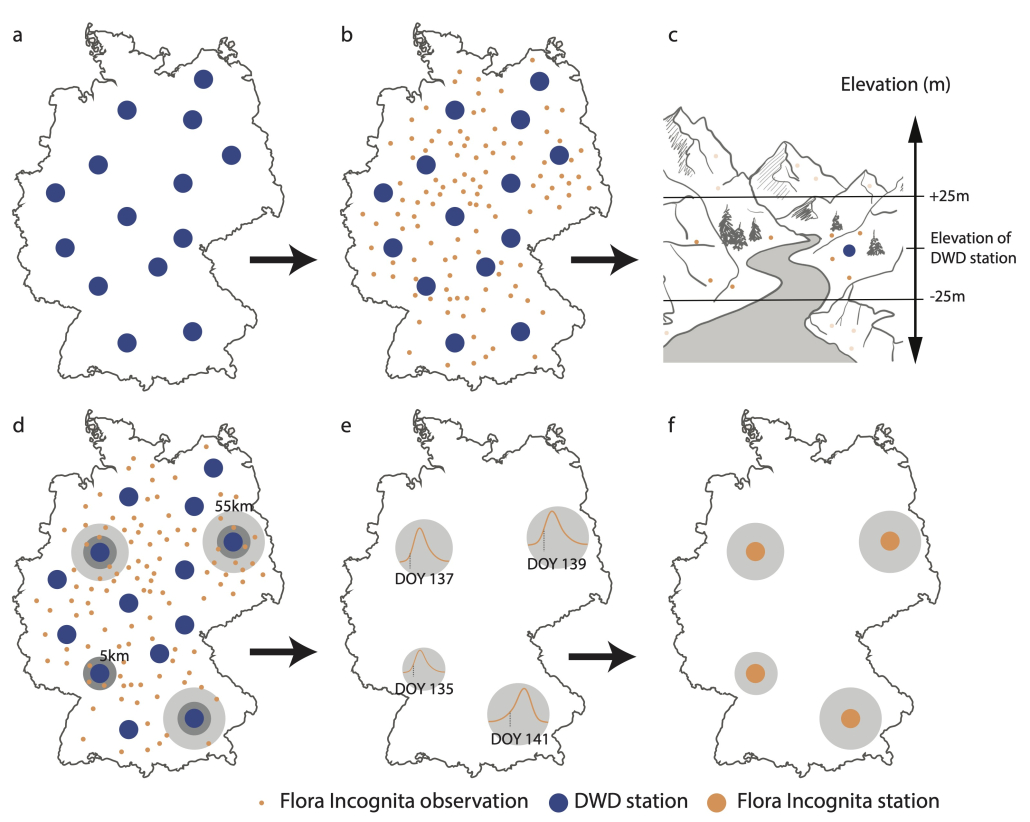
Den entscheidenden Durchbruch zur flächendeckenden Anwendung brachten Millionen von Pflanzenbeobachtungen, die durch Citizen Science und KI-gestützte Bestimmungsmethoden ermöglicht wurden.
„Pflanzenbestimmungs-Apps erleichtern Bürger:innen die Erfassung der Biodiversität erheblich und liefern eine große Zahl an Beobachtungen, insbesondere im urbanen Raum“, betont Dr. Jana Wäldchen, Forschungsgruppenleiterin am MPI für Biogeochemie und Co-Leiterin des Flora-Incognita-Projektes.
Prof. Patrick Mäder, Co-Projektleiter von Flora Incognita, ergänzt: „Lange galt KI-gestützte Pflanzenbestimmung als kaum realisierbar und die daraus entstehenden Daten als zu unstrukturiert für die Forschung. Diese Studie zeigt eindrucksvoll das Gegenteil: Innovative Fragestellungen über große räumliche Skalen brauchen neue Datenströme – und Flora Incognita hat sich hierfür zu einem wichtigen Werkzeug etabliert.“
Was Pflanzen über Städte verraten
Bebaute Gebiete sind europaweit wärmer, trockener und dunkler als die Grünflächen der jeweiligen Städte. Ihre Böden sind alkalischer, salziger, nährstoffärmer und stärker durch mechanische Bodenbearbeitung gestört als die in Parks oder Stadtwäldern. Letztere übernehmen wichtige Ökosystemleistungen wie Kühlung und Wasserspeicherung. Die Unterschiede innerhalb einer Stadt können so groß sein wie zwischen Städten, die Tausende Kilometer voneinander entfernt liegen – wie etwa zwischen Madrid und Stockholm. Doch trotz der Vielfalt innerhalb einzelner Städte sind sich die bebauten Flächen europaweit sehr ähnlich. Dies ist ein Hinweis auf urbane Homogenisierung. Stadtwälder hingegen bewahren ihre ursprünglichen lokalen Umweltbedingungen und damit die natürliche Vielfalt.
„Städte sind Orte, an denen Umweltprobleme sichtbar werden – aber auch Lösungen entstehen können“, betont Tautenhahn. Pflanzen sind mehr als nur eine grüne Kulisse: Sie machen verborgene Umweltbedingungen sichtbar und liefern neue Ansätze für Monitoring, Forschung, Politik und Stadtplanung – auf dem Weg zu nachhaltigen, resilienten und lebenswerten Städten.
Forschungsförderung
Diese Studie entstand im Rahmen des Projektes Flora Incognita Moni: Biodiversitätsmonitoring mit Flora Incognita, als gemeinsames Projekt der Technischen Universität Ilmenau und des Max-Planck-Instituts für Biogeochemie Jena. Es wird durch das Bundesamt für Naturschutz und das Nationale Monitoringzentrum zur Biodiversität mit Mitteln des Bundesministeriums für Umwelt, Klimaschutz, Naturschutz und nukleare Sicherheit gefördert.
Die Publikation
Tautenhahn, S., Jung, M., Rzanny, M., Mäder, P., Reichstein, M., Ahrens, B., Bebber, A., Boho, D., Chytrý, M., Dengler, J., Jansen, F., Katal, N., Midolo, G., Tichý, L., Walther, S., Weber, U., Wittich, H. C. & Wäldchen, J. (2026). Urbanization signatures on climate and soils uncovered by crowd-sensed plants. Nat Cities. https://doi.org/10.1038/s44284-025-00378-9
 https://creativecommons.org/licenses/by-sa/4.0/deed.en
https://creativecommons.org/licenses/by-sa/4.0/deed.en